딥러닝(Deep Learning)은 인공지능(AI)의 한 분야로, 복잡한 데이터를 분석하고 패턴을 학습하는 데 탁월한 성능을 보입니다. 이번 포스팅에서는 딥러닝의 기초 개념부터 실제 응용 사례, 그리고 개발 환경 설정까지를 다루어 봅니다. 이를 통해 딥러닝을 처음 접하는 분들도 쉽게 이해할 수 있도록 돕겠습니다.
1. 딥러닝 개요
딥러닝은 인공신경망(Artificial Neural Network, ANN)을 기반으로 하여 여러 층의 뉴런이 상호작용하며 데이터를 처리합니다. 딥러닝의 주요 모델로는 다음과 같은 것들이 있습니다:
- 컨볼루션 신경망(CNN): 주로 이미지 처리에 사용됩니다. CNN은 이미지의 특징을 추출하는 데 효과적이며, 자율 주행 자동차, 안면 인식 기술 등에서 널리 사용되고 있습니다.
- 순환 신경망(RNN): 시계열 데이터나 자연어 처리에 적합합니다. RNN은 이전 단계의 출력을 다음 단계의 입력으로 사용하는 구조로, 번역, 음성 인식 등에서 강력한 성능을 발휘합니다.
- 트랜스포머(Transformer): 자연어 처리와 같은 복잡한 데이터에도 뛰어난 성능을 발휘합니다. 트랜스포머 모델은 병렬 처리 능력이 뛰어나며, GPT 모델이 대표적인 예입니다.
딥러닝 모델은 이미 여러 산업 분야에서 폭넓게 활용되고 있습니다.
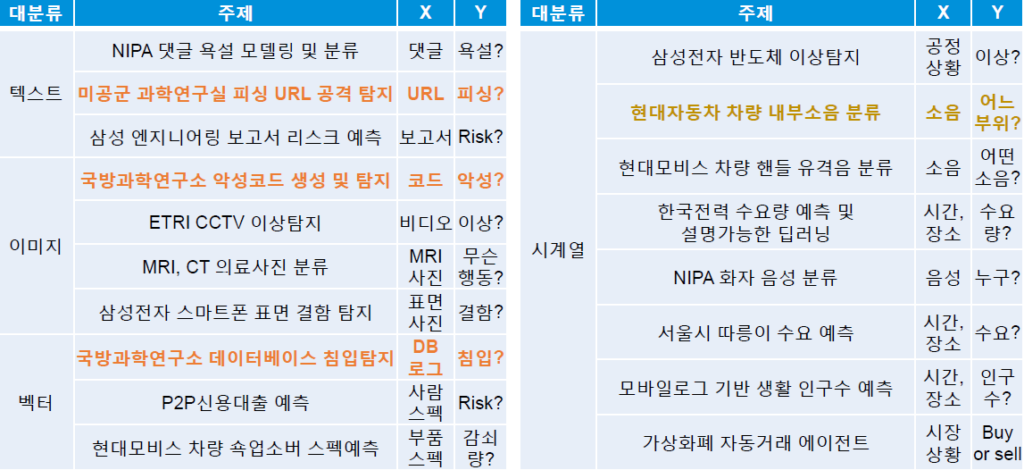
2. 현재 딥러닝 성능
딥러닝 기술의 발전은 눈부십니다. 미드저니(MidJourney) AI는 콜로라도 주립 미술대회에서 우승할 정도로 고도화된 이미지 생성 능력을 보여주었으며, Chat-GPT는 복잡한 교육 커리큘럼도 생성할 수 있습니다. 이러한 기술들은 단순한 모델을 넘어 복잡한 문제를 해결하는 데 있어 실용적인 도구로 자리 잡고 있습니다.
또한, 음향 데이터를 처리하는 AI 기술도 발전하여, 유명 가수의 목소리를 사용한 음향 스타일 전이 등의 응용이 가능합니다. 포토샵 AI는 이미지 생성과 수정에서 혁신적인 기능을 제공하며, 사용자의 창의성을 극대화합니다.
3. 딥러닝 개발 환경 설정
딥러닝을 시작하려면 적절한 딥러닝 개발 환경 설정을 하는 것이 중요합니다. 이 과정에서는 구글 코랩(Google Colab)과 아나콘다(Anaconda)를 이용하여 개발 환경을 설정하는 방법을 설명합니다. 이번 교육과정에서는 아나콘다를 사용하도록 하겠습니다.
1) 구글 코랩(Google Colab)
구글 코랩은 클라우드 기반의 무료 Jupyter 노트북 환경으로, 별도의 설치 없이도 즉시 사용할 수 있습니다. GPU를 지원하여 빠른 연산이 가능하며, 어디서나 동일한 환경을 제공합니다.
- Google Colab 페이지로 이동합니다.
- 구글 계정으로 로그인합니다.
- 새로운 노트북을 생성하여 바로 Python 코드를 실행할 수 있습니다.
2) 아나콘다(Anaconda) 설치 및 설정
아나콘다는 로컬에서 Python 기반의 데이터 과학 플랫폼을 제공하며, 다양한 라이브러리를 쉽게 설치하고 관리할 수 있습니다. TensorFlow, Keras, Pandas 등의 라이브러리를 설치하여 딥러닝 모델을 로컬에서 실행할 수 있습니다.
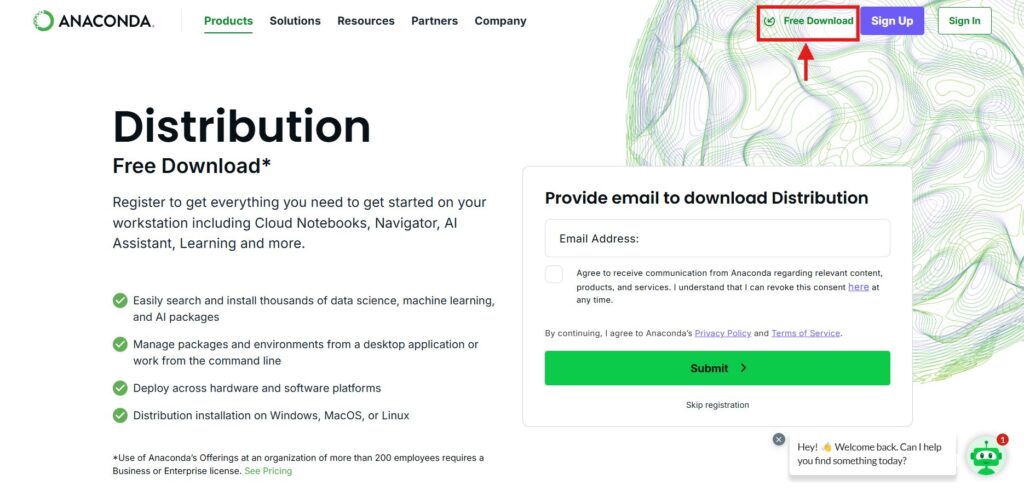
아나콘다 다운로드 및 설치 과정:
- 아나콘다 다운로드:
- Anaconda 공식 웹사이트로 이동합니다.
- 페이지 중간의 “Download” 버튼을 클릭합니다.
- 자신의 운영 체제에 맞는 설치 파일을 선택하여 다운로드합니다.
- 아나콘다 설치:
- 다운로드가 완료되면 설치 파일을 실행합니다.
- “Next”를 클릭하여 설치를 시작합니다.
- 설치 경로를 선택하거나 기본 경로로 설치를 진행합니다.
- “Add Anaconda to my PATH environment variable” 체크박스를 선택한 후 “Install”을 클릭합니다.
- 이 옵션은 필수는 아니지만, 선택하면 명령 프롬프트에서 아나콘다를 쉽게 사용할 수 있습니다.
- 설치가 완료되면 “Finish”를 클릭합니다.
- 아나콘다 환경 설정:
- 설치가 완료되면 “Anaconda Prompt”를 실행합니다.
- Windows에서 “시작” 버튼을 클릭하고 “Anaconda Prompt”를 검색하여 실행할 수 있습니다.
- 아래 명령어를 통해 가상환경을 생성하고 필요한 라이브러리를 설치합니다.
# 가상환경 생성 및 활성화
conda create -n tensorflow python=3.9 ipykernel
activate tensorflow
# 필요한 라이브러리 설치
conda install tensorflow keras notebook ipykernel- 가상환경에서 작업 폴더를 생성하고, Jupyter Notebook을 실행합니다.
# 작업 폴더로 이동
cd C:\workspace
# Jupyter Notebook 실행
jupyter notebook- 웹 브라우저에서 자동으로 Jupyter Notebook이 열리며, 여기서 Python 코드를 작성하고 실행할 수 있습니다.
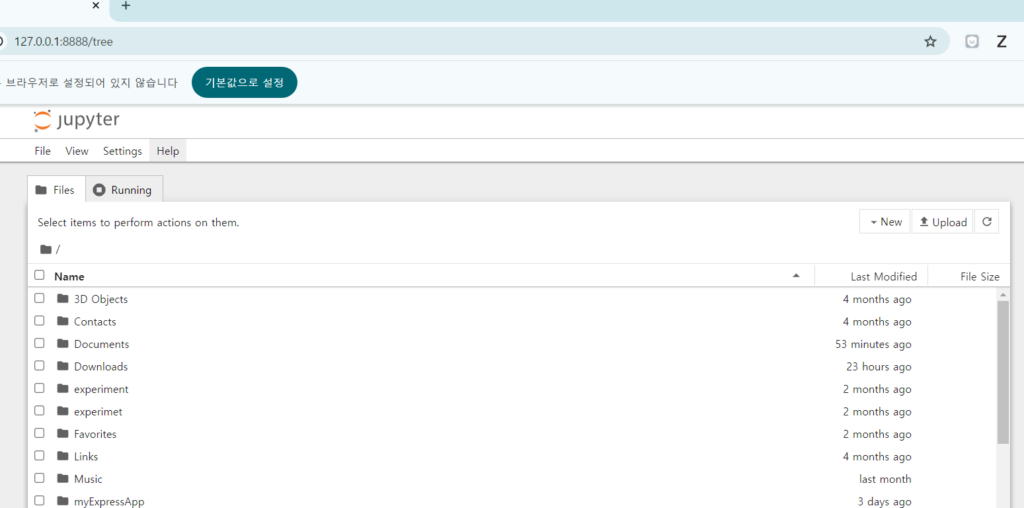
또는
윈도우 버튼을 누르고 jupyter notebook 앱을 실행시킨 후

서버 내용 중에 접속 주소가 있으니 그것으로 접속하면 됩니다.
4. 손글씨 분류 예제
딥러닝의 기본 개념을 이해하기 위해 MNIST 데이터셋을 활용한 손글씨 분류 예제를 진행할 수 있습니다. 이 예제에서는 다음과 같은 과정을 거칩니다:
- 데이터 로딩 및 전처리: 손글씨 이미지를 로딩하여 학습과 테스트용으로 분할합니다.
import numpy as np
import pandas as pd
from sklearn.model_selection import train_test_split
from tensorflow.keras import utils
# MNIST 데이터셋 로딩
mnist_csv = pd.read_csv('./dataset/mnist_train.csv', header=None, skiprows=1).values
# 데이터 분할
train, test = train_test_split(mnist_csv, test_size=0.3, random_state=1)
X_train, Y_train = train[:, 1:], train[:, 0]
X_test, Y_test = test[:, 1:], test[:, 0]
# 범주형으로 변환
Y_train_cat = utils.to_categorical(Y_train)
Y_test_cat = utils.to_categorical(Y_test)
- MLP 모델 설계: 다층 퍼셉트론(MLP) 신경망을 설계하고, 손글씨 이미지를 분류하도록 학습시킵니다.
from tensorflow.keras.layers import Input, Dense
from tensorflow.keras.models import Model
# MLP 모델 설계
mlp_input = Input(shape=(784,))
h = Dense(256, activation='tanh')(mlp_input)
h = Dense(128, activation='tanh')(h)
mlp_output = Dense(10, activation='softmax')(h)
mlp_model = Model(mlp_input, mlp_output)
mlp_model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy'])
mlp_model.summary()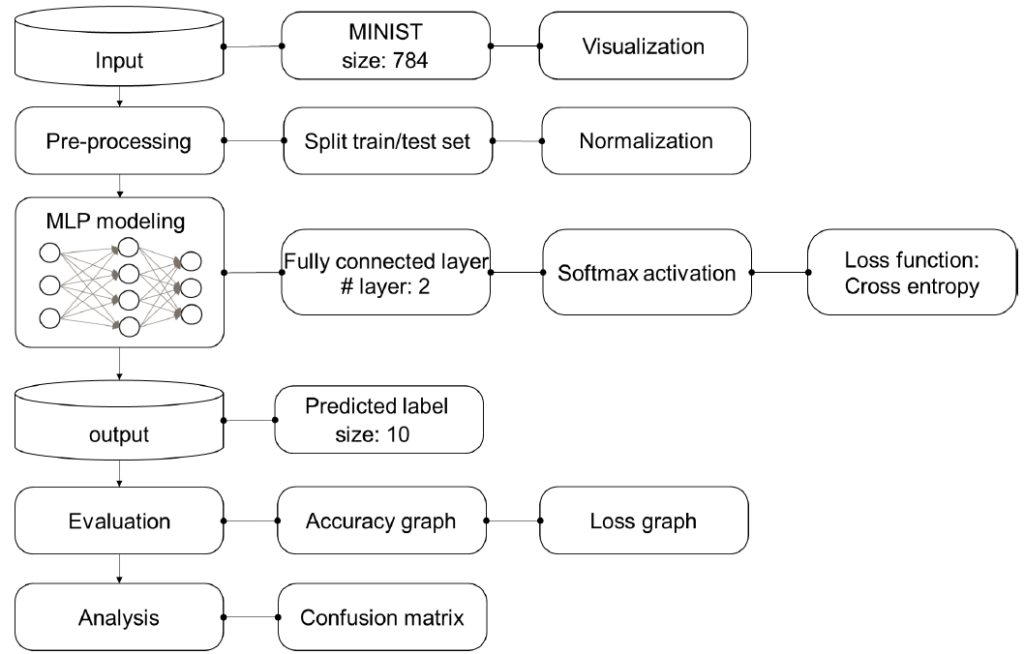
- 모델 학습: 학습 커브를 시각화하고, 모델의 성능을 평가합니다.
# 모델 학습
model_history = mlp_model.fit(X_train, Y_train_cat, validation_data=(X_test, Y_test_cat), epochs=100, batch_size=256, shuffle=True, verbose=2)
# 학습 커브 시각화
import matplotlib.pyplot as plt
plt.plot(model_history.history['loss'])
plt.plot(model_history.history['val_loss'])
plt.xlabel('epochs'), plt.ylabel('Loss')
plt.legend(['Train', 'Test'])
plt.show()- 정확도 및 혼동행렬 분석: 분류 결과의 정확도, 정밀도(Precision), 재현율(Recall)을 분석하고 혼
동행렬을 시각화하여 모델의 성능을 평가합니다.
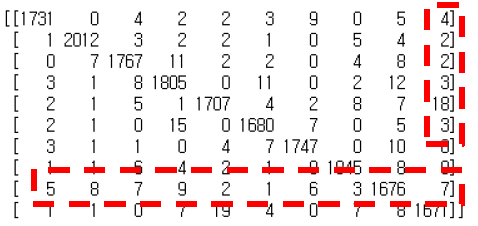
from sklearn.metrics import confusion_matrix
import numpy as np
# 혼동행렬 시각화
Y_test_cat_hat = mlp_model.predict(X_test)
Y_test_hat = np.argmax(Y_test_cat_hat, axis=1)
print(confusion_matrix(Y_test_hat, Y_test))이와 같은 실습을 통해 딥러닝 모델의 구조와 학습 과정을 체험할 수 있습니다.
결론
딥러닝은 복잡한 문제를 해결하는 데 강력한 도구로 자리 잡고 있습니다. 이번 포스팅에서는 딥러닝의 기초 개념부터 개발 환경 설정, 그리고 실습 예제까지 다루어 보았습니다. 앞으로도 다양한 실습과 응용 사례를 통해 딥러닝을 깊이 있게 이해하고 활용할 수 있기를 바랍니다.
이 포스팅이 유익했다면, 구독과 좋아요를 눌러주세요. 더 많은 딥러닝 관련 정보를 지속적으로 제공하도록 하겠습니다.