이전 포스팅(딥러닝 개발 환경 설정 가이드 – CSAI)에서 우리는 딥러닝의 기초 개념을 살펴보고 Google Colab과 Anaconda를 사용해 개발 환경을 설정했습니다. 이제, 이러한 지식을 실제 프로젝트에 적용할 차례입니다. 이번 포스팅에서는 손글씨 분류를 하는 간단한 신경망을 단계별로 구축하는 방법을 안내합니다.
우선은 MNIST 데이터셋을 다운로드 받도록 합시다.
1. 문제 이해하기: 손글씨 분류
이번 프로젝트의 목표는 손글씨로 작성된 숫자(0~9)를 이미지에서 정확히 분류하는 모델을 만드는 것입니다. 이를 위해 MNIST 데이터셋을 사용할 것입니다. 이 데이터셋은 42,000개의 라벨이 지정된 손글씨 숫자 이미지로 구성되어 있으며, 각 이미지의 크기는 28×28 픽셀입니다. 이 데이터셋은 다양한 형태의 숫자와 서로 비슷한 숫자들이 많아 신경망 훈련에 적합합니다.
MNIST 이미지 예시:

각 이미지에는 0에서 9 사이의 숫자가 라벨로 지정되어 있으며, 우리의 작업은 이 라벨을 예측하는 모델을 만드는 것입니다.
2. 데이터 로드 및 전처리
먼저, MNIST 데이터셋을 로드하고 모델에 맞게 전처리해야 합니다.
import numpy as np
import pandas as pd
from sklearn.model_selection import train_test_split
from tensorflow.keras import utils
# MNIST 데이터셋 로드
mnist_csv = pd.read_csv('./dataset/mnist_train.csv', header=None, skiprows=1).values
# 데이터셋을 학습 및 테스트 세트로 분할
train, test = train_test_split(mnist_csv, test_size=0.3, random_state=1)
X_train, Y_train = train[:, 1:], train[:, 0]
X_test, Y_test = test[:, 1:], test[:, 0]
# 라벨을 원-핫 벡터로 변환
Y_train_cat = utils.to_categorical(Y_train)
Y_test_cat = utils.to_categorical(Y_test)원-핫 인코딩이란?
원-핫 인코딩은 범주형 라벨을 신경망이 이해할 수 있는 형식으로 변환하는 방법입니다. 예를 들어, 숫자가 3이라면 원-핫 인코딩은 이를 [0, 0, 0, 1, 0, 0, 0, 0, 0, 0]로 변환합니다.
3. 데이터 정규화 및 시각화
모델에 데이터를 입력하기 전에 정규화를 진행해야 합니다. 정규화는 픽셀 값을 0에서 255까지의 범위에서 0에서 1 사이의 범위로 조정하여 모델 훈련을 더 효율적으로 만듭니다.
# 데이터셋 정규화
X_train_norm = X_train / 255.0
X_test_norm = X_test / 255.0
# 학습 이미지 중 하나를 시각화
import matplotlib.pyplot as plt
import numpy as np
plt.imshow(np.reshape(X_train_norm[0], (28, 28)), cmap=plt.cm.Blues)
plt.show()정규화의 중요성:
정규화는 입력 값의 범위를 유사하게 만들어 모델의 성능과 안정성을 향상시킵니다.
4. 신경망 모델 구축
이제 Keras를 사용해 간단한 다층 퍼셉트론(MLP) 모델을 구축해 보겠습니다. 우리 모델은 ReLU 활성화 함수를 사용하는 두 개의 은닉층을 가집니다. ReLU는 학습 과정에서 특정 문제를 피하고 효율적으로 작동하기 때문에 널리 사용됩니다.
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense
# MLP 모델 구축
mlp_model = Sequential()
mlp_model.add(Dense(512, activation='relu', input_shape=(784,)))
mlp_model.add(Dense(256, activation='relu'))
mlp_model.add(Dense(10, activation='softmax'))
mlp_model.summary()레이어 설명:
- 입력층: 784개의 픽셀 입력을 받습니다.
- 은닉층: ReLU 활성화 함수와 함께 512 및 256 유닛을 사용합니다.
- 출력층: 10개의 유닛과 소프트맥스 활성화 함수로 숫자 클래스(0-9)를 예측합니다.
5. 모델 컴파일 및 학습
이제 모델을 컴파일해야 합니다. 손실 함수로 카테고리컬 크로스 엔트로피를, 옵티마이저로 확률적 경사 하강법(SGD)을 사용하겠습니다.
from tensorflow.keras.optimizers import SGD
# 모델 컴파일
sgd = SGD(lr=0.005)
mlp_model.compile(loss='categorical_crossentropy', optimizer=sgd, metrics=['accuracy'])
# 모델 학습
model_history = mlp_model.fit(X_train_norm, Y_train_cat, epochs=15, batch_size=256, verbose=2, validation_data=(X_test_norm, Y_test_cat), shuffle=True)모델 학습:
훈련 과정에서 모델은 손실 함수를 기준으로 가중치를 조정하여 정확도를 높입니다. 에포크(epoch)를 거치며 데이터셋을 여러 번 학습시켜 모델을 최적화합니다.
6. 모델 성능 평가
모델을 학습한 후, 테스트 데이터를 사용해 성능을 평가하는 것이 중요합니다. 학습 에포크 동안의 손실 및 정확도를 시각화하여 모델의 성능을 분석합니다.
# 손실 곡선 그리기
plt.plot(model_history.history['loss'])
plt.plot(model_history.history['val_loss'])
plt.title('모델 손실')
plt.ylabel('손실')
plt.xlabel('에포크')
plt.legend(['Train', 'Test'], loc='right')
plt.show()
# 정확도 곡선 그리기
plt.plot(model_history.history['accuracy'])
plt.plot(model_history.history['val_accuracy'])
plt.title('모델 정확도')
plt.ylabel('정확도')
plt.xlabel('에포크')
plt.legend(['Train', 'Test'], loc='right')
plt.show()이 곡선들이 의미하는 바는?
- 손실 곡선: 에포크마다 손실이 감소하는지 확인하여 모델이 학습하고 있는지 평가합니다.
- 정확도 곡선: 학습 및 테스트 데이터에 대한 모델의 정확도를 보여줍니다.
7. 혼동 행렬을 사용한 오류 분석
모델의 성능을 더 자세히 분석하기 위해 혼동 행렬을 사용해 보겠습니다. 이를 통해 모델이 어떤 숫자를 얼마나 자주 잘못 예측하는지 확인할 수 있습니다.
from sklearn.metrics import confusion_matrix
import itertools
# 혼동 행렬 함수
def plot_confusion_matrix(model_input, feature, label, class_info):
pred=model_input.predict(feature)
cnf_matrix=confusion_matrix(np.argmax(label,axis=1),np.argmax(pred,axis=1))
plt.figure()
plt.imshow(cnf_matrix,interpolation='nearest',cmap=plt.cm.Blues)
tick_marks= np.arange(len(class_info))
plt.xticks(tick_marks,class_info,rotation=45)
plt.yticks(tick_marks,class_info)
thresh=cnf_matrix.max()/2.
for i, j in itertools.product(range(cnf_matrix.shape[0]), range(cnf_matrix.shape[1])):
plt.text(j, i, cnf_matrix[i, j], horizontalalignment="center", color="white"
if cnf_matrix[i, j] > thresh else "black")
plt.tight_layout()
plt.ylabel('True label')
plt.xlabel('Predicted label')
plt.show()
# 혼동 행렬 그리기
label = ['0','1','2','3','4','5','6','7','8','9']
plot_confusion_matrix(mlp_model, X_test_norm, Y_test_cat, class_info=label)혼동 행렬이란?
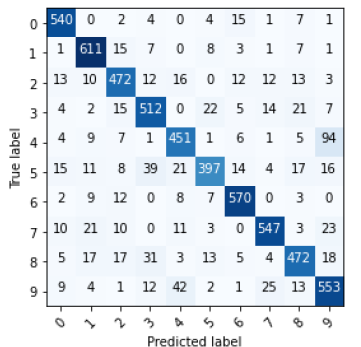
혼동 행렬은 위 이미지와 같이 모델이 각 클래스(숫자)를 얼마나 잘 예측했는지 보여주는 표입니다. 이를 통해 모델이 어떤 숫자를 혼동하는지 확인할 수 있습니다.
결론
이번 포스팅에서는 손글씨 숫자를 분류하는 신경망을 구축, 학습, 평가하는 과정을 다루었습니다. 데이터 전처리부터 모델 성능 평가까지 각 단계를 이해함으로써 다양한 작업에 딥러닝 모델을 적용할 수 있는 기초를 마련할 수 있습니다.
딥러닝을 배우는 과정에서 연습과 실험이 중요합니다. 다양한 아키텍처, 옵티마이저, 데이터셋을 시도해보며 모델 성능에 어떤 영향을 미치는지 직접 경험해보세요.
더 깊이 있는 딥러닝 기술과 전략에 대해 배우고 싶다면, 다음 포스팅을 기대해 주세요!
이 가이드가 도움이 되셨다면, 구독과 좋아요를 눌러주세요. 궁금한 점이나 의견이 있다면 댓글로 남겨주세요!