안녕하세요! 구글이 2026년 2월 19일, 새로운 차원의 추론 능력을 갖춘 AI 모델 제미나이 3.1 프로(Gemini 3.1 Pro)를 전격 공개했습니다.
이번 제미나이 3.1 프로는 단순한 버전 업그레이드를 넘어, 기존 AI들이 어려워하던 ‘처음 보는 논리 패턴’과 ‘복잡한 에이전트 워크플로우’를 해결하는 데 특화되어 설계되었습니다. 과연 현존 최강의 AI 자리를 두고 경쟁 모델들과 비교했을 때 어느 정도의 성취를 이루었는지, 새롭게 업데이트된 다양한 벤치마크 결과를 통해 객관적으로 살펴보겠습니다.
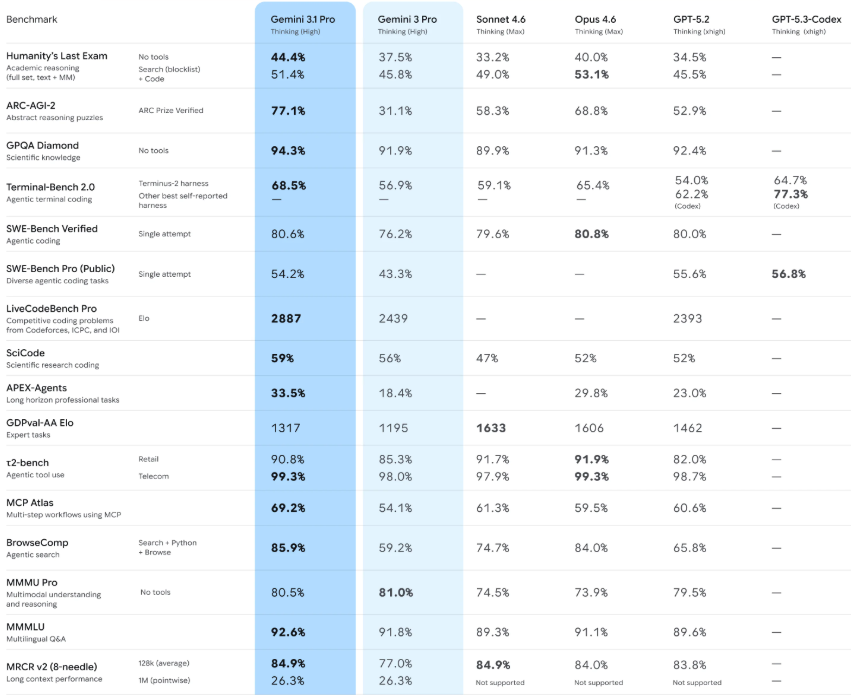
▲ 제미나이 3.1 프로 벤치마크 비교표 (참고 이미지)
1. 벤치마크 하이라이트: 압도적인 추론 능력의 향상 🧠
가장 눈에 띄는 성과는 단연 ‘추상 논리 추론’ 영역입니다. 기존 언어 모델들이 암기력에 의존하던 한계를 넘어, 제미나이 3.1 프로는 스스로 규칙을 파악하고 문제를 해결하는 진정한 의미의 추론 능력을 증명했습니다.
- ARC-AGI-2 (추상 논리 추론):77.1%
- 완전히 새로운 퍼즐과 논리 패턴을 푸는 이 테스트에서 전작인 제미나이 3 프로(31.1%) 대비 무려 2배 이상(148%) 성능이 향상되었습니다. 경쟁 모델인 GPT-5.2(52.9%)와 클로드 오퍼스 4.6(68.8%)을 크게 따돌리며 압도적인 1위를 기록했습니다.
- Humanity’s Last Exam (인류의 마지막 시험):44.4% (도구 미사용 기준)
- 최상위 수준의 학술적 추론 능력을 묻는 이 테스트에서도 경쟁사 모델(GPT-5.2: 34.5%, 클로드 오퍼스 4.6: 40.0%)을 제치고 가장 높은 점수를 달성했습니다.
2. 실무 및 코딩 성능: 에이전트형 워크플로우의 진화 💻
단순한 코드 생성을 넘어, 실제 개발 환경에서 복잡한 과제를 수행하는 에이전트(Agentic) 성능 역시 크게 도약했습니다.
- SWE-Bench Verified (코딩 실무):80.6%
- 실제 소프트웨어 엔지니어링 문제를 해결하는 능력을 평가하며, 최고 수준인 클로드 오퍼스 4.6(80.8%)과 사실상 동률을 이루며 코딩 분야의 최강자 반열에 올랐습니다.
- LiveCodeBench Pro (경쟁 코딩 Elo):2887점
- 알고리즘 문제 해결 능력을 체스 점수처럼 나타내는 지표로, 복잡한 코딩 경연 수준의 문제에서 타 모델들을 크게 앞서고 있습니다.
- Terminal-Bench 2.0 (에이전트 터미널 코딩):68.5%
- 개발자 터미널 환경에서 구조적인 계획과 명령어를 직접 실행하는 실무 능력에서도 높은 점수를 보였습니다.
3. 다방면의 멀티모달 및 지식 평가 📊
전문 지식과 다국어, 그리고 시각 정보를 포함한 복합적인 이해 능력에서도 빈틈없는 모습을 보여줍니다.
- GPQA Diamond (대학원 수준 과학 지식):94.3%
- 물리, 화학, 생물 등 박사급 지식이 필요한 문항에서도 94% 이상의 놀라운 정답률을 보이며 뛰어난 전문 지식을 입증했습니다.
- MMMLU (멀티모달 다국어 이해):92.6%
- 다양한 언어로 주어지는 텍스트 및 시각 자료 혼합 문제에서 강력한 이해도를 보여줍니다.
📝 마무리하며: AGI를 향한 의미 있는 한 걸음
벤치마크 결과를 종합해 보면, 제미나이 3.1 프로는 단순히 아는 것이 많은 AI에서 **”스스로 생각하고 문제를 해결하는 AI”**로 확실하게 진화했습니다. 특히 ARC-AGI-2에서 보여준 비약적인 성장은 AI의 추론 능력이 질적인 임계점을 넘고 있음을 시사합니다.
현재 제미나이 앱, 노트북LM(NotebookLM), 구글 AI 스튜디오 등을 통해 프리뷰 버전으로 직접 경험해 볼 수 있습니다. 복잡한 데이터를 다루거나, 코딩 실무에 깊이 있는 AI 어시스턴트가 필요하다면 제미나이 3.1 프로가 최적의 선택이 될 것입니다.